
Can we visualise style and speaker separations in Flowtron?
Published:
This week NVIDIA’s new TTS model, Flowtron [4], has been released. I worked a lot with the Mellotron and its score parser for the Eurovision AI Song Contest (where we got third place, hooray!), so I was really interested in checking out this new model.
I am supervising a Master’s project now in emotional speech synthesis and after listening to the examples here, I was wondering if we could do the same. With some help from Rafael Valle through GitHub, I could quickly set up the style transfer code. One of the advice he gave is to take the mean of the “posterior evidence (z)”. This is a technically more correct name for the latent factors in inverse autoregressive flow.
This is a new technique used in style transfer called the reference audio (RA) based method, which I first read about in [1]. The problem with using single audio for style transfer is that you are not sure if your neural net will understand what is exactly what you want to transfer. However, if you use either the average of the latent factors (or global style tokens) obtained from multiple audios, then you get a more robust style. Additionally, with the Flowtron, you can sample from the latent space to get more varied prosody. More complicated tail-sampling techniques are applicable like in [2], which would probably result in even more varied intonation.
Let’s hear some examples using the RAVDESS [3] dataset:
| Emotion | Audio |
|---|---|
| Happy | |
| Angry |
They are not perfect, but I really like that they are putting the emotion very delicately in the speech signal, even though I am using the more acted samples from the RAVDESS.
Another cool thing that you can do is interpolation between emotions:
| Emotion | Happy-Sad |
|---|---|
| 0 (Happy) | |
| 0.2 | |
| 0.4 | |
| 0.6 | |
| 0.8 | |
| 1 (Sad) |
I was also wondering if you could visualise the latent space of the Flowtron if we can obtain the clusters for the emotions. And this is what I found:
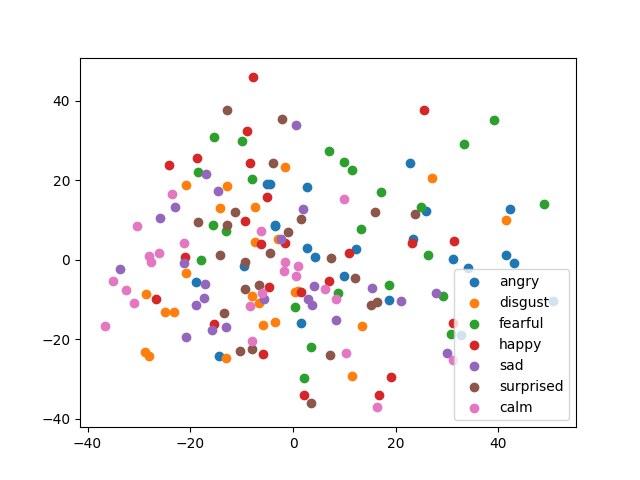
What’s happening? There are clearly no emotion separations here. Then I plot the speakers, which you can see below (selected three here for clarity):
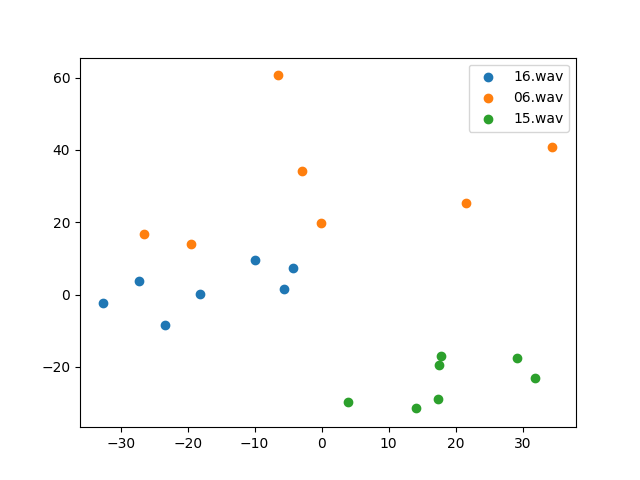
I believe what’s happening is that we can’t visualise the separation of speakers and styles at the same time, because they are opposing objectives. In style separation, we want different speakers close, styles apart; in speaker separation vice versa. This really shows one important difference between Tacotron 2 GST and the Flowtron: Tacotron2 encodes speakers separately, while the Flowtron doesn’t.
It’s a really nice model, and I recommend everyone to try it, maybe it gives you some new ideas for your own research!
References:
[1] KWON, Ohsung, et al. An Effective Style Token Weight Control Technique for End-to-End Emotional Speech Synthesis. IEEE Signal Processing Letters, 2019, 26.9: 1383-1387.
[2] HODARI, Zack; WATTS, Oliver; KING, Simon. Using generative modelling to produce varied intonation for speech synthesis. arXiv preprint arXiv:1906.04233, 2019.
[3] Livingstone SR, Russo FA (2018) The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5): e0196391. https://doi.org/10.1371/journal.pone.0196391.
[4] VALLE, Rafael, et al. Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis. arXiv preprint arXiv:2005.05957, 2020.