
Residual networks for resisting noise: analysis of an embeddings-based spoofing countermeasure
Published in Speaker Odyssey 2020, 2020
Recommended citation: Halpern, Kelly, van Son, Alexander (2020). " Analysing an embeddings-based spoofing countermeasure in noise; ODYSSEY 2020. 1(1). http://karkirowle.github.io/files/Odyssey2020_spoofingResNet_Halpern_et_al.pdf
This is our supplementary page for our paper: “Residual networks for resisting noise: analysis of an embeddings-based spoofing countermeasure”
In our paper, we analyse two CQT-based spoofing countermeasures in various realistic noisy conditions. We also explore some explainable audio approaches to offer the human listener insight into the types of information exploited by the network in discriminating spoofed speech from real speech.
Abstract: In this paper we propose a spoofing countermeasure based on Constant Q-transform (CQT) features with a ResNet embeddings extractor and a Gaussian Mixture Model (GMM) classifier. We present a detailed analysis of this approach using the Logical Access portion of the ASVspoof2019 evaluation database, and demonstrate that it provides complementary information to the baseline evaluation systems. We additionally evaluate the CQT-ResNet approach in the presence of various types of real noise, and show that it is more robust than the baseline systems. Finally, we explore some explainable audio approaches to offer the human listener insight into the types of information exploited by the network in discriminating spoofed speech from real speech.
GradCAM-based examples
The approaches below are based on the same principle as explainable machine learning techniques for computer vision applications. The GradCAM technique is used to obtain a saliency map for the audio sample, using the publicly available library keras-vis library. The saliency map shows which parts of the CQT-spectrogram are the most sensitive to the class activation decision. In other words, this shows which parts are the most important. This saliency map can be used to threshold the spectrogram for its salient parts, as it is just a ”2D array of importance”. Finally, the new spectrogram can be resynthesised to generate audio using a Griffin-Lim vocoder.
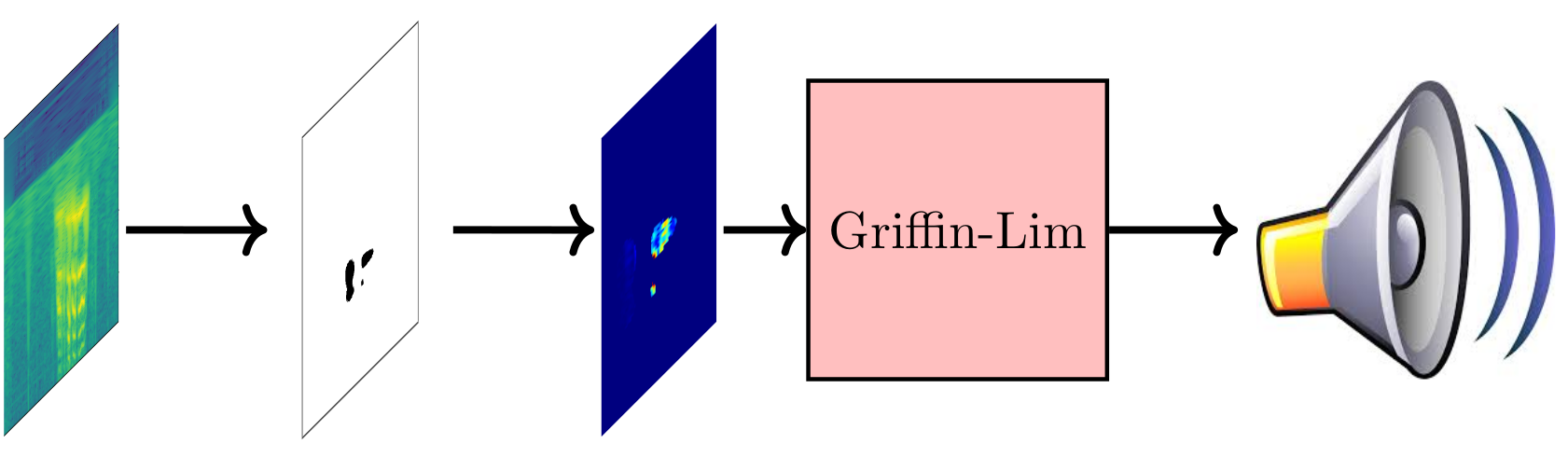
In the below examples you will first hear an original utterance from the evaluation set, then a resynthesised example, and finally the explainable audio example. In most examples, you can hear that it is the rhythm of speech that seems to be the most important, as this can be clearly identified from most of these audio samples. Categories, like example A12 shows that there is a characteristic noise for a particular spoofing category which is learned by our neural network.
| Spoofing class | Audio |
|---|---|
| Bonafide | |
| A07 | |
| A08 | |
| A09 | |
| A10 | |
| A11 | |
| A12 | |
| A13 | |
| A14 | |
| A15 | |
| A16 | |
| A17 | |
| A18 | |
| A19 |
Mean audio
A limiting factor when listening to individual audio samples (to assess naturalness, for example), is that our brains inevitably focus on the semantic content instead of any acoustic anomalies. By playing back multiple audio samples simultaneously, we can simulate a cocktail party scenario, where the listener is forced to listen to the acoustics.
In the setup below, we created mean audio samples by grouping individual samples based on the CM scores.
For each spoof type, we collect the 100 closest files to each side of the CM decision boundary (i.e. bonafide and spoof),and we call this “close”. In order to let the listener experiment with the effects of the scores, we also provided two other categories, Bonafide/Spoof (Medium) and Bonafide/Spoof (Far). The former contains the average of hundred (100) examples, thousand (1000) utterances away from the boundary. Similarly, the latter contains the average of hundred (100) examples, but two thousand (2000) utterances away from the boundary.
For example, in A18, you can observe a very particular type of noise more agressively present as you proceed from Spoof (Close) to Spoof (Far).
| Class boundary | Bonafide (Far) | Bonafide (Medium) | Bonafide (Close) | Spoof (Close) | Spoof (Medium) | Spoof (Far) |
|---|---|---|---|---|---|---|
| Bonafide-A07 | ||||||
| Bonafide-A08 | ||||||
| Bonafide-A09 | ||||||
| Bonafide-A10 | ||||||
| Bonafide-A11 | ||||||
| Bonafide-A12 | ||||||
| Bonafide-A13 | ||||||
| Bonafide-A14 | ||||||
| Bonafide-A15 | ||||||
| Bonafide-A16 | ||||||
| Bonafide-A17 | ||||||
| Bonafide-A18 | ||||||
| Bonafide-A19 |