
A glimpse at Interspeech 2019 papers
Published:
Interspeech is drawing closer day by day, so I went through the planned schedule to cherry pick the titles that I found a bit more interesting than the others (from the perspective of pathological speech synthesis). I would like to use this opportunity to also go through the authors and show some impressive results.
An investigation on speaker-specific articulatory synthesis with speaker independent articulatory inversion - Aravind Illa
As I spent quite a bit of time already with articulatory inversion and synthesis during the first year of my PhD, I came across Illa’s work a few times. His last paper on articulatory to acoustic inversion have used a combination of 1D convolutional neural network with BLSTM. Usually, MFCCs are used for the inversion, but here are a filterbank is learnt and the most interesting bit is Figure 4 on the paper:
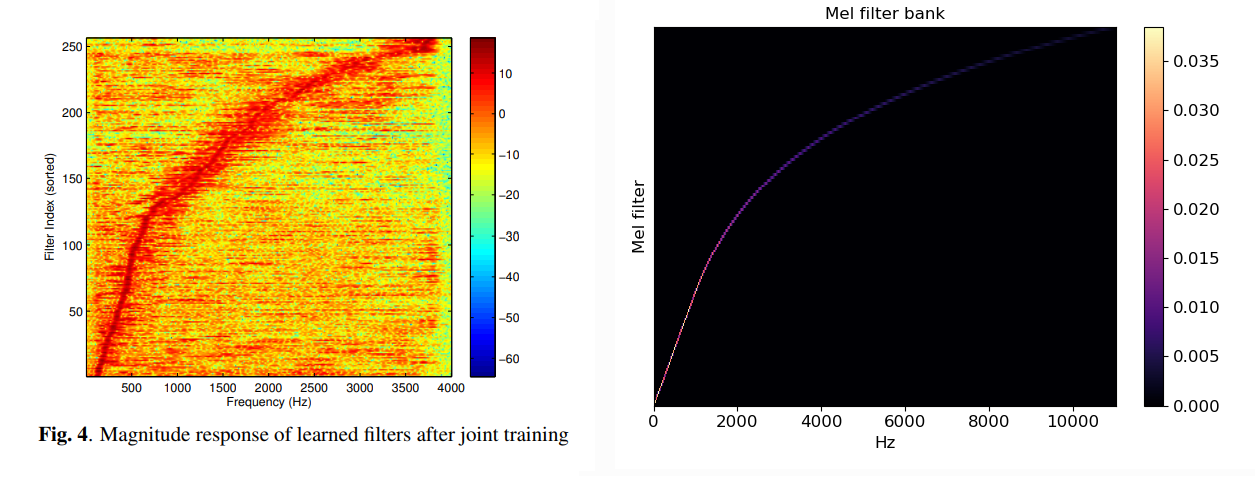
Note the similarities, but be aware that the scale of the axes are slightly different.
Multi-corpus acoustic-to-articulatory speech inversion - Nadee Seneviratre
I know less about this author, last year her group studied “Noise Robust Articulatory to Acoustic Speech Inversion” in their paper. Their endeavour is to use articulatory representations for automatic speech recognition, and they are exploring possibilities to improve from all aspects i.e synthetic data using TADA (an articulation model based on ODEs), data augmentation with nosie and now it seems to be that that corpus combination is going to be the next attempt.
I am very keen on hearing their results as it is not straightforward to combine datas from different corpus (TORGO, MOCHA-TIMIT, MNGU0) and different modalities (X-ray microbeam, EMA), so I will be interested in their approach taken.
Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams - Guanlong Zhao
Actually, the preprint is already available for this one, here. The authors derive a new architecture for foreign accent conversions. There are couple of interesting points, like they use WaveGlow, which is an invertible neural network variant of WaveNet. They also use phonetic posteriors, which seem to be getting more popular. I didn’t know anything about them, but actually the idea seems to be quite straightforward. PPG is just a time-dependent categorical distributions, so effectively it models the probability and uncertainty about the current phones at a given time.
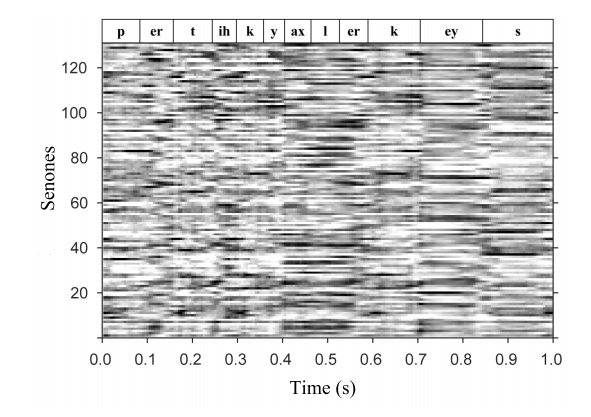
Example of a PPG from paper "PHONETIC POSTERIORGRAMS FOR MANY-TO-ONE VOICE CONVERSION WITHOUT PARALLEL DATA TRAINING"
I find that this paper has many good ideas that I would definitely want to try in my research, in oral cancer speech prediction we are also interested in keeping the speaker identity, while messing with the qualitative - articulatory - aspects of speech. And pronounciation is a fundamentally articulatory process as I see.